Hirdetés
Hisz Ön abban az elgondolásban, hogy ha valamit közzétesznek az interneten, örökre meghirdetik? Nos, ma eloszlatjuk ezt a mítoszot.
Az igazság az, hogy sok esetben teljesen meg lehet szüntetni az információkat az internetről. Persze, van olyan weboldal, amelyet töröltek, ha a Wayback gép, jobb? Igen, teljesen. A Wayback Machine-ben olyan weblapokról van feljegyzés, amelyek visszamenőleg évek óta állnak fenn - olyan oldalak, amelyeket nem talál a Google kereséssel, mert a weboldal már nem létezik. Valaki törölte, vagy a weboldalt leállították.
Tehát nem lehet megkerülni, igaz? Az információ örökre beágyazódik az internet kőbe, ott lehet generációk számára látni? Nos, nem pontosan.
Az igazság az, hogy bár nehéz lehet vagy lehetetlen elpusztítani a főbb híreket, amelyek az egyik hírportálról vagy blogról a másikra elterjedtek, mint egy vírus, valójában elég könnyű egy weblapot vagy több weboldalt teljesen megsemmisíteni az összes létező nyilvántartásból - eltávolítani ezt az oldalt mind a keresőmotorok számára, mind a az
Wayback gép Az új visszatérő gép lehetővé teszi, hogy vizuálisan visszautazzon az internetes időbeÚgy tűnik, hogy a Wayback Machine 2001. évi elindítása óta a webhelytulajdonosok úgy döntöttek, hogy kidobják az Alexa-alapú hátteret és újratervezik azt saját nyílt forráskódjukkal. Miután a ... Olvass tovább . Természetesen van egy fogás, de mi megkapjuk.3 módszer a blogoldalak eltávolításához az internetről
Az első módszer az, amelyet a webhelytulajdonosok többsége használ, mivel nem tudnak jobbat - egyszerűen csak törölnek weboldalakat. Ennek oka az lehet, hogy rájött, hogy webhelyén ismétlődő tartalom van, vagy mert van olyan oldala, amelyet nem szeretne megjeleníteni a keresési eredmények között.
Egyszerűen törölje az oldalt
Az a probléma, hogy teljesen törli az oldalakat a webhelyről, az, hogy mivel már létrehozta az oldalt a net, valószínűleg vannak linkek a saját webhelyén, valamint külső linkek más webhelyekről az adott webhelyre oldalt. Amikor törli, a Google azonnal felismeri a te oldalad hiányzó oldalát.

Tehát az oldal törlésekor nemcsak problémát okozott a „Nem található” feltérképezési hibákkal kapcsolatban, hanem mindenki számára is problémát okozott, aki valaha is hivatkozott az oldalra. Általában azok a felhasználók, akik az említett külső linkek egyikével jutnak el az Ön webhelyére, látják a 404-es oldalt, amely nem egy nagy probléma, ha valami hasonlót használ a Google egyedi 404 kódjához, hogy hasznos javaslatokat adjon a felhasználóknak, vagy alternatívákat. De azt gondolnád, hogy lehet kevésbé kevés módja az oldalak törléséhez a keresési eredményekből anélkül, hogy a 404-es elemeket az összes meglévő bejövő hivatkozásra rúgná, ugye?
Nos, vannak.
Egy oldal eltávolítása a Google keresési eredményeiből
Mindenekelőtt meg kell értenie, hogy ha a weboldal, amelyet el szeretne távolítani a Google keresési eredményeiből, nem a saját webhelye oldala, akkor nincs szerencséje, hacsak nincs jogi ok, vagy ha a webhely az Ön személyes adatait online közzétette Ön nélkül engedély. Ha ez a helyzet, akkor használja a Google-t eltávolítási hibaelhárító kérés benyújtása az oldal eltávolításához a keresési eredményekből. Ha érvényes esetünk van, akkor talán sikerrel is jár, ha eltávolítja az oldalt - természetesen még nagyobb sikert is elérhet kapcsolatfelvétel a weboldal tulajdonosával Hogyan lehet eltávolítani a hamis személyes információkat az internetrőlAz online adatvédelem már nem garantált. Tanulja meg, hogyan jelenthet be egy webhelyet, és hogyan távolíthatja el a személyes információkat az internetről. Olvass tovább ahogy leírtam, hogyan kell megtenni 2009-ben.
Most, ha az a oldal, amelyet el szeretne távolítani a keresési eredményekből, a saját webhelyén található, szerencséd van. Csak annyit kell tennie, hogy létrehoz egy robots.txt fájlt, és győződjön meg arról, hogy letiltotta vagy a keresett eredményekben nem kívánt oldalt, vagy a teljes könyvtárat, amelynek tartalmát nem kívánja indexelni. Így néz ki egy oldal blokkolása.
Felhasználói ügynök: * Tiltás: /my-delt-article-that-i-want-removed.html
A robotok megakadályozhatják a webhely teljes könyvtárainak feltérképezését az alábbiak szerint.
Felhasználói ügynök: * Tiltás: / tartalom-személyes dolgok /
A Google kiváló támogatási oldal amely segít létrehozni egy robots.txt fájlt, ha még soha nem hozott létre. Ez rendkívül jól működik, ahogy a közelmúltban egy cikkben kifejtettem szindikációs ügyletek strukturálása A szindikációs ajánlatok tárgyalása és a keresési rangsor védelmeA szindikálás manapság minden düh. De hirtelen észreveheti, hogy a szindikációs partner magasabbra van sorolva, mint Ön az eredetileg írt történet keresési eredményeiben! Védje keresési rangsorát. Olvass tovább hogy ne bántsanak téged (arra kéri a szindikciós partnereket, hogy ne engedjék indexelni oldalaikat az Ön szindikált oldalán). Miután a saját szindikációs partner hozzájárult ehhez, a blogom tartalmát lemásoló oldalak teljesen eltűntek a keresési listákból.

Csak a fő webhely jelenik meg a harmadik helyen azon oldal számára, ahol felsorolják a címünket, de blogom most fel van sorolva az első és a második helyen is; olyasmi, ami szinte lehetetlen lett volna, ha egy magasabb szintű webhely indexált volna a másolatot.
Sokan nem veszik észre, hogy ezt az Internet Archive (a Wayback Machine) segítségével is meg lehet valósítani. Íme a sor, amelyet hozzá kell adnia a robots.txt fájlhoz annak megvalósításához.
Felhasználói ügynök: ia_archiver. Tiltás: / minta-kategória /
Ebben a példában azt mondom az Internet Archívumnak, hogy távolítson el mindent a webhelyem minta kategória alkönyvtárában a Wayback Machineből. Az internetes archívum a kirekesztés súgó oldalán ismerteti, hogyan kell ezt megtenni. Ez az, ahol magyarázzák, hogy „Az Internet Archívum nem érdekli hozzáférést olyan webhelyekhez vagy más internetes dokumentumokhoz, amelyek szerzői nem akarják anyagukat a gyűjteményben.”
Ez ellentétes az általánosan elterjedt hiedelemmel, hogy bármi, amit az interneten közzétesznek, az örökkévalóságig felsöpör az archívumba. Nem - a tartalmat birtokló webmesterek kifejezetten eltávolíthatják a tartalmat az archívumból a robots.txt megközelítés használatával.
Távolítson el egy egyéni oldalt metacímkékkel
Ha csak néhány egyedi oldala van, amelyeket el szeretne távolítani a Google Keresési Találatokból, akkor valójában nem kell a robots.txt megközelítést használnia egyáltalán hozzáadhatja a helyes “robotok” metacímkét az egyes oldalakhoz, és megmondhatja a robotoknak, hogy ne indexeljék vagy kövessék a linkeket az egész oldalon oldalt.
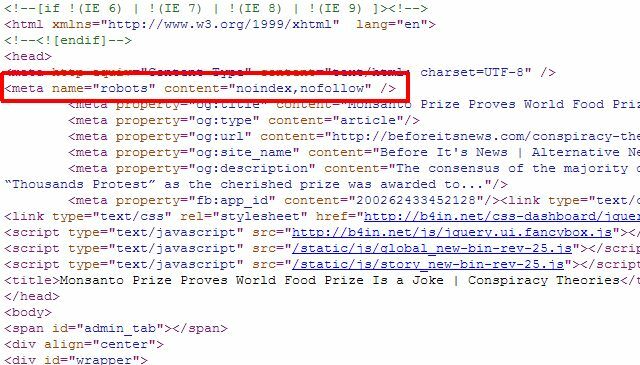
A fenti „robotok” meta segítségével megakadályozhatja a robotokat az oldal indexelésében, vagy kifejezetten megmondhatja a Google robotnak nem indexelni, így az oldalt csak eltávolítják a Google keresési eredményeiből, és más keresőrobotok továbbra is hozzáférhetnek az oldalhoz tartalom.
Teljesen rajtad múlik, hogyan szeretné kezelni, hogy a robotok mit tesznek az oldallal, és hogy az oldal szerepel-e a listán. Néhány egyedi oldal esetében ez lehet a jobb megközelítés. A teljes tartalomjegyzék eltávolításához használja a robots.txt metódust.
A tartalom „eltávolításának” ötlete
Ez a fejét forgatja a teljes tartalom törlése az internetről. Technikai szempontból, ha eltávolítja az összes saját hivatkozást a webhely egyik oldalára, és eltávolítja azt a Google Keresőből és a Internetes archívum a robots.txt technikával, az oldal minden szándékra és célra „törölve” az internetről. A hűvös dolog az, hogy ha vannak létező hivatkozások az oldalra, akkor ezek a linkek továbbra is működnek, és nem fog 404-es hibát idézni elő a látogatók számára.
Ez egy „szelídebb” megközelítés, ha eltávolítjuk a tartalmat az internetről anélkül, hogy teljesen elrontanánk a webhely jelenlegi link-népszerűségét az interneten keresztül. Végül, hogy miként kezeli a tartalmakat, amelyeket a keresőmotorok és az Internet Archívum összegyűjtenek, az ön feladata, de mindig ne feledje, hogy annak ellenére, amit az emberek mondnak az interneten közzétett dolgok élettartamáról, ez valójában teljesen az ön belsejében van ellenőrzés.
Ryan BSc villamosmérnöki diplomával rendelkezik. 13 évet dolgozott az automatizálás területén, 5 évet az informatika területén, és most Apps Engineer. A MakeUseOf volt vezérigazgatója, az adatmegjelenítéssel foglalkozó nemzeti konferenciákon beszélt, és szerepelt a nemzeti televízióban és rádióban.